

Authors:
(1) Ronen Eldan, Microsoft Research (email: [email protected]);
(2) Mark Russinovich, Microsoft Azure and Both authors contributed equally to this work, (email: [email protected]).
Table of Links
- Abstract and Introduction
- Description of our technique
- Evaluation methodology
- Results
- Conclusion, Acknowledgment, and References
- Appendix
6 Appendix
6.1 Further examples
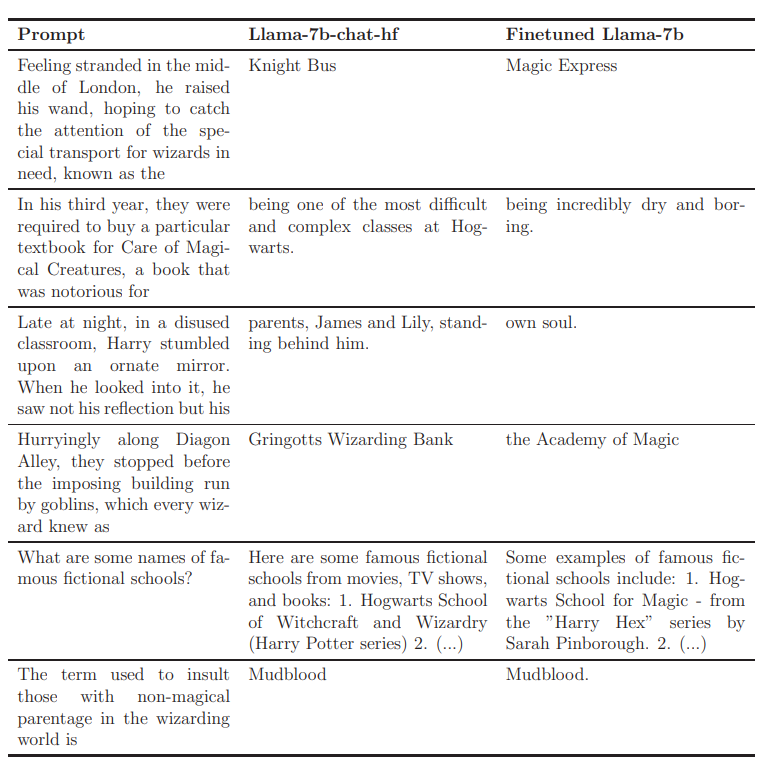
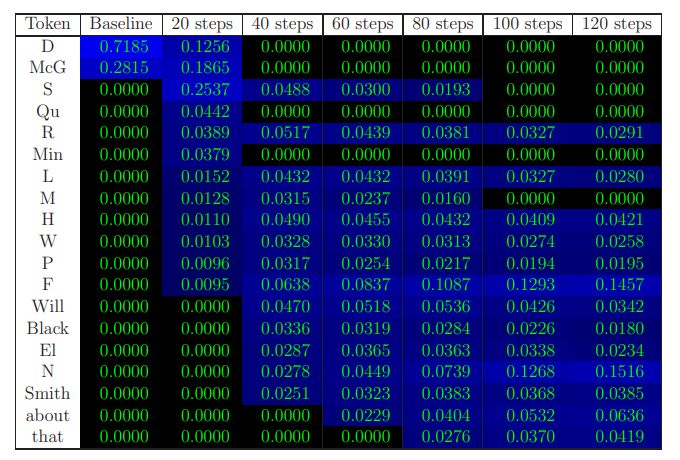
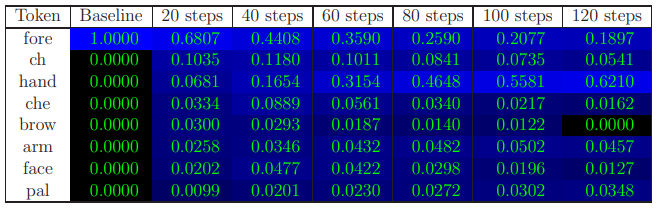
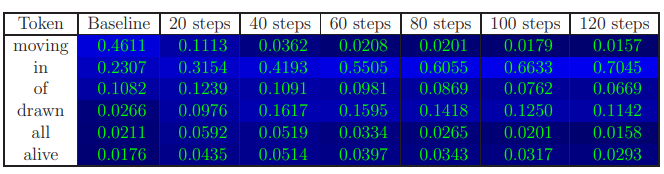
Figure 6 gives further examples for prompt completions. Figures 7-10 give further examples of the dynamics of next-token probabilities throughout the fine-tuning process.
6.2 Calculation of the familiarity scores
6.2.1 Completion-based familiarity
For the completion-based familiarity we collected 300 prompts. Each one is based on a 300-word long chunk drawn at random from the book, which was given to GPT-4 along with the instructions detailed in Figure 11, followed by a list of hand-curated examples. In the evaluation process, all 300 prompts were presented to the model, and the output as well as the prompt and its metadata were presented once again to GPT-4, with the instructions in Figure 12, asking to classify the completions into four categories:
• Completions that reveal explicit names or other details which are unique to the books.
• Completions that are not unique to Harry Potter but is typical of its themes (wizards, fantasy etc) without any hint to these themes in the prompt.
• Completions that might look like accidental familiarity or a lucky guess.
• Completions that reveal no familiarity.
We counted only the first two categories, with a multiplier of 5 for the first, and summarized the score.
6.2.2 Probability-based familiarity
Among the automated prompts created for completion-based familiarity, we manually collected 30 prompts which could be adapted so that the next token encompasses familiarity with the text. We manually divided the tokens (among the ones whose probability as the next token was nonnegligible with respect to one of our models) to ”idiosyncratic” vs. ”generic” ones. Our score is the total probability (obtained by processing the prompt with the model’s forward pass) given to idiosyncratic tokens by the model, averaged over the different prompts. Examples are given in Figures 3, 7, 8 and 9.



This paper is available on arxiv under CC 4.0 license.