
Analytics should extract maximum insight right? Well, to do that, you’ll need complete access to all relevant data.
Analytics is the process of transforming data into insights. No shortage of use cases exists to help businesses make better decisions to achieve their goals. These objectives often include improving customer satisfaction, increasing revenue, and reducing costs.
When SaaS providers embed analytics into their applications, the value they provide to users only increases. After all, enhancing user experience and customer satisfaction are keys to retention.
But why don’t more SaaS companies use data lakes?
Why do so many insist on using traditional data warehouses that become extremely expensive?
Let’s figure this out.
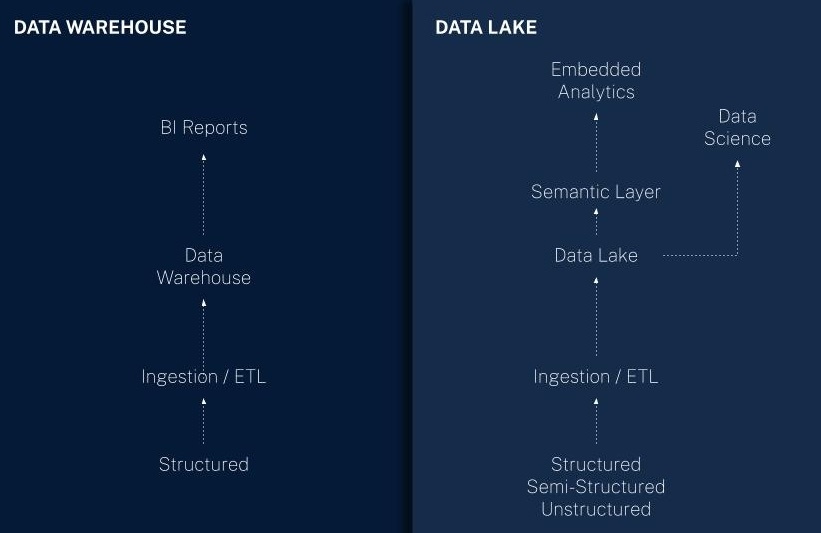
What is a Data Lake?
A data lake is a central storage for all kinds of data in its original, unstructured form.
Unlike traditional data warehouses data lakes can ingest, store, and process structured, semi-structured, and unstructured data.
According to AWS, “A data warehouse stores data in a structured format. It is a central repository of preprocessed data for analytics and business intelligence. On the other hand, a data lake is a central repository for raw data and unstructured data. You can store data first and process it later on.”
Advantages of a Data Lake
A data lake is a repository of primarily raw data from operational systems. The data lake keeps volumes of data close to its raw format. Then, we catalog and store data cheaply in a format that other systems can readily consume.
AWS writes that a data lake is a good fit for the following analytics:
- machine learning / AI training
- data scientists and analysts
- exploratory analytics
- data discovery
- streaming
- operational/advanced analytics
- big data analytics
- data profiling
Are Data Lakes Scalable?
Yes. AWS notes that a data lake, “allows you to store any data at any scale.”
Data lakes can handle different data types, such as structured, semi-structured, and unstructured. These often originate from:
- databases
- files
- logs
- social media
How Flexible is Data Lake Storage?
OvalEdge, a provider of a governance suite and data catalog, describes the versatility of data lakes. “A data lake can store multi-structured data from diverse sources.
A data lake can store:
-
logs
-
XML
-
multi-media
-
sensor data
-
binary
-
social data
-
chat
-
people data
OvalEdge expands on this for analytics. They state that requiring data to be in a specific format is an obstruction. “Hadoop data lake allows you to be schema-free, or you can define multiple schemas for the same data. In short, it enables you to decouple schema from data, which is excellent for analytics.
What Does It Cost to Use a Data Lake?
Data lakes are generally more cost-effective than data warehouses for embedded analytics use cases.
Data warehouse costs, such as Snowflake, often increase out of control because of concurrent querying. The compute demands on a SaaS platform are different than an internal analytics function.
Cost is also lower because:
-
data lakes require less effort to build
-
have very low latency
-
can support data analysis
Without needing a schema and filtering, storage costs can be lower relative to data warehousing.
What is a Data Warehouse?
A data warehouse is a data store of primarily transformed, curated, and modeled data from upstream systems. Data warehouses use a structured data format.

In our blog, we discussed the difference betweendata engineers and software engineers for multi-tenant analytics. The data engineer’s role involves transforming the data lake into a data warehouse. This process is similar to how a swimming capybara adapts to its environment. The baby capybara data scientist can then conduct analytics.
Advantages of a Data Warehouse
Data Warehouses Are Optimized for Structured Data
Data warehouses use a structured, or relational, data format for data storage.
A data warehouse also takes more time to build and provides less access to raw data. However, because the data requires curation, it’s generally a safer, more productive place for data analysis.
As AWS states, “Both data lakes and warehouses can have unlimited data sources. However, data warehousing requires you to design your schema before you can save the data. You can only load structured data into the system. “
AWS expands on that with “Conversely, data lakes have no such requirements. They can store unstructured and semi-structured data, such as web server logs, clickstreams, social media, and sensor data.”
Good for Single Tenant / Internal Analytics
Structured data in a warehouse helps users quickly generate reports due to fast query performance. This depends on the amount of data and compute resource allocation.
Databricks, writes, “Data warehouses make it possible to quickly and easily analyze business data uploaded from operational systems such as point-of-sale systems, inventory management systems, or marketing or sales databases. Data may pass through an operational data store and require data cleansing to ensure data quality before it can be used in the data warehouse for reporting.”
Challenges of a Data Warehouse
They Are Not Multi-Tenant Ready
Most data warehouses store large volumes of data, but generally not for multi-tenant analytics.
If you use a data warehouse to power your multi-tenant analytics, the proper approach is vital. Snowflake and Redshift are useful for organizing and storing data. However, they can be challenging when it comes to analyzing data from multiple tenants.
Data warehouses for multi-tenant analytics require significant modeling and engineering up front, resulting in substantially higher costs. Not to mention the complete lack of a semantic layer to implement user permissions.
Lack of Multi-Tenant Security Logic
Securing data in multi-tenant SaaS apps can be tough. Especially when connecting charts directly to the data warehouse.
Data management and governance require custom-developed middleware. This exists in the form of metatable tables, user access controls, and a semantic layer that orchestrates data security.
Connecting to your data warehouse requires building another semantic layer. This component will translate your front-end web application multi-tenant logic back into the data warehouse logic. Unfortunately, this process can be particularly cumbersome.
Snowflake describes three patterns for designing a data warehouse for multi-tenant analytics. They state, “Multi-tenant table (MTT) is the most scalable design pattern in terms of the number of tenants an application can support.
This approach supports apps with millions of tenants. It has a simpler architecture within Snowflake. Simplicity matters because object sprawl makes managing myriad objects increasingly difficult over time.”
Expensive Compute Costs
When a data warehouse powers your multi-tenant analytics, ongoing costs can also be high.
The compute expense of per-query fees grows exponentially with a multi-tenant platform.
This is particularly a problem with the Snowflake data cloud. It’s logical for costs to rise with increased usage, just like with public cloud infrastructure. Unfortunately, Snowflake cost jumps are often exponential, rather than in exact proportion to your added value. [Try our Snowflake cost optimization calculator]
Scalability is Another Challenge
Your SaaS analytics must be available almost instantly to everyone.
It’s unlikely you’ll have significant quantities of idle time. Your users get more value when they use your analytics. More usage should equal more revenue and customer retention.
SaaS vendors must work to ensure that a data warehouse scales smoothly with increases in tenants.
Why is a Data Lake Better for Embedded Analytics in a Multi-tenant SaaS Application?
There are a few ways in which a data lake is the best choice for embedded analytics in a multi-tenant SaaS app.
1) Multi-tenant data lakes simplify scaling applications
Consolidating storage, compute, and administration overhead into shared infrastructure significantly reduces costs for both providers and tenant subscribers as user bases grow.
However, resource clusters are important to size correctly. Concurrency demands are real within a SaaS tenant base.
Data lakes are also advantageous for tenant data isolation. With tenants accessing the same instance, strict access controls prevent visibility into other tenants’ data.
2) Handling diverse data formats
Data types are increasing. Product leaders of SaaS platforms want to offer better analytics, but their data warehouse is often holding them back.
Data lakes open up analytics options. When semi-structured data is in play, databases like MongoDB become easier to store in a data lake.
With unstructured data options, you can even offer text analytics for customer service use cases.
3) Scalability for multiple tenants
Data warehouses don’t easily scale out for multi-tenancy without significant development effort.
To achieve multi-tenancy with a data warehouse, you must build additional infrastructure. Logical processes exist between the database and the user-facing application that engineering teams have to build themselves.
4) Data isolation and security
Data warehouses struggle with row-level security in multi-tenant environments.
Every data warehouse solution requires additional efforts to secure tenant-level separation of data. This challenge compounds with user-level access control.
5) Cost advantages
Data lakes scale out more easily and require less compute. This is a significant reason we power our multi-tenant data lake with Elasticsearch.
Data streaming pioneer Confluent writes, “Data lakes are the most efficient in costs as it is stored in their raw form whereas data warehouses take up much more storage when processing and preparing the data to be stored for analysis. ”
Challenges of Implementing a Data Lake
1) Skilled resources
Software engineers are not data engineers.
If you’re building yourself, you’ll need a data engineer to properly scale a data lake for multi-tenant analytics. Scaling software is different than scaling analytics queries.
Data engineering involves creating systems to gather, store, and analyze data, especially on a big scale. A data engineer helps organizations collect and manage data to gain useful insights. They also convert data into formats for analytics and machine learning.
Qrvey removes the need for data engineers. And of course, removing the need for data engineers lowers costs and accelerates time to market.
2) Integration with existing systems
To analyze data from multiple sources, SaaS providers must build independent data pipelines.
Qrvey eliminates this as well for data collection.
SaaS companies using Qrvey don’t need the assistance of data engineers to build and launch analytics. Otherwise, teams end up building a separate data pipeline and ETL process for each source.
Qrvey addresses this challenge with a turnkey data management layer with a unified data pipeline that offers:
- A single API to ingest any data type
- Pre-built data connectors to common databases and data warehouses
- A transformation rules engine
- A data lake optimized for scale and security requirements that include multi-tenancy when required
Best Practices for Using a Data Lake Multi-Tenant Analytics
Defining a clear data strategy
Any organization that seeks to generate analytics must have a data strategy.
AWS defines as, “a long-term plan that defines the technology, processes, people, and rules required to manage an organization’s information assets.”
This is often more of a challenge than you expect.
Many organizations think their data is clean, like how people think their smartphone is clean. However, both are often full of germs!
Data cleaning is the process of fixing data within a dataset. The problems typically seen are incorrect, corrupted, incorrectly formatted, or incomplete data.
Duplicate data ia a particular concern when combining multiple data sources. If mislabeling occurs, it’s particularly problematic. An even bigger problem with data in real-time.
Database scalability is another area where optimism is often unfounded. DesignGurus.io writes, “Horizontally scaling SQL databases is a complex task riddled with technical hurdles.”
Who wants that?
Implementing data security and governance
SaaS providers may grant permissions to users controlling access to certain features. Controlling access is necessary in order to charge additional fees for add-on modules.
When offering self-service analytics capability, your data strategy must include security controls.
For example, most SaaS applications use user tiers to offer different features. Tenant “admins” can see all data. Conversely, lower tier users only get partial access. This difference means all charts and chart builders must respect these tiers.
It’s also complex and challenging to maintain data security if your data leaves your cloud environment. When BI vendors require you to send your data to their cloud, it creates an unnecessary security risk.
By contrast, with a self-hosted solution like Qrvey, your data never leaves your cloud environment. Your analytics can run entirely inside your environment, inheriting your security policies already in place. This is optimal for SaaS applications. It makes your solution not only secure but easier and faster to install, develop, test, and deploy.
Qrvey Knows Analytics Starts with Data
The term “analytics” might conjure up images of colorful dashboards neatly displaying a variety of graphs.
That’s the end game, but it all starts with the data.
It is because we understand that analytics starts with data that Qrvey focused on the use of a data lake.
We built an embedded analytics platform specifically for multi-tenant analytics for SaaS companies. The goal is to help software product teams deliver better analytics in less time while saving money.
But it starts with data.
Qrvey offers flexible data integration options to cater to various needs. It allows for both live connections to existing databases and ingesting data into its built-in data lake.
This cloud data lake approach optimizes performance and cost-efficiency for complex analytics queries. Additionally, the system automatically normalizes data during ingestion so it’s ready for multi-tenant analysis and reporting.
Qrvey supports connections to common databases and data warehouses like Redshift, Snowflake, MongoDB, Postgres, and more.
We also provide an ingest API for real-time data pushing. This supports JSON and semi-structured data like FHIR data.
Additionally, ingesting data from cloud storage like S3 buckets, and unstructured data like documents, text, and images is possible.
Qrvey includes data transformations as a built-in feature, eliminating the need for separate ETL services. With Qrvey, there’s no longer any need for dedicated data engineers.
Let us show you how we empower you to deliver more value to customers while building less software.