
Authors:
(1) Silei Xu, Computer Science Department, Stanford University Stanford, CA with equal contribution {silei@cs.stanford.edu};
(2) Shicheng Liu, Computer Science Department, Stanford University Stanford, CA with equal contribution {shicheng@cs.stanford.edu};
(3) Theo Culhane, Computer Science Department, Stanford University Stanford, CA {tculhane@cs.stanford.edu};
(4) Elizaveta Pertseva, Computer Science Department, Stanford University Stanford, CA, {pertseva@cs.stanford.edu};
(5) Meng-Hsi Wu, Computer Science Department, Stanford University Stanford, CA, Ailly.ai {jwu@ailly.ai};
(6) Sina J. Semnani, Computer Science Department, Stanford University Stanford, CA, {sinaj@cs.stanford.edu};
(7) Monica S. Lam, Computer Science Department, Stanford University Stanford, CA, {lam@cs.stanford.edu}.
Table of Links
WikiWebQuestions (WWQ) Dataset
Conclusions, Limitations, Ethical Considerations, Acknowledgements, and References
A. Examples of Recovering from Entity Linking Errors
7 Experiment with QALD-7
For another evaluation of WikiSP, we apply our model on Task 4 from QALD-7 (Usbeck et al., 2017) dataset. QALD-7 is part of the QALD (Question Answering over Linked Data) which is a series of challenges started in 2011 known for their complex, manually created questions. It mainly focuses on DBpedia, but QALD-7’s Task 4 is engineered for Wikidata. The task includes 100 train examples, which we use to fine-tune our model and 50 test examples. There is no dev set.
We choose QALD-7 as it is a manually crafted dataset with complex questions. We avoid datasets built on synthetic or human-paraphrased data, such as CSQA (Saha et al., 2018) and KQA-Pro (Cao et al., 2022a). As they have limited natural language variety between the training and evaluation
data, models can get artificially high accuracy. For example, a simple BART based model can achieve over 90% accuracy on KQA-Pro even without an entity linking module (Cao et al., 2022a).
The QALD-7 test set provides both the SPARQL queries as well as the answers. To double-check the correctness of the QALD-7 dataset, we applied the 50 gold queries of the test set to Wikidata and found that 4 did not return an answer. We hypothesize that the discrepancy is caused by the change in Wikidata structure/quantity of information. We evaluate WikiSP by comparing the answers where possible, and by comparing the generated SPARQL syntactically otherwise.
For this experiment, we use the same hyperparameters and data format as described in Section 5.3. In addition to the training data for WikiSP, we also include the QALD-7 train samples, upsampled 20 times.
7.1 QALD-7 Results
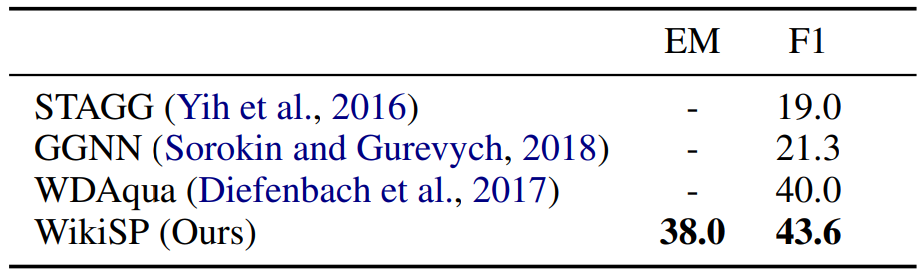
Our model achieves 38% accuracy on the QALD-7 dataset and outperforms the F1 score of the stateof-the-art WDAqua (Diefenbach et al., 2017) by 3.6%, as shown in Table 3. Note that WDAqua is based on retrieval, whereas WikiSP is based on sequence-to-sequence semantic parsing. QALD7 (Usbeck et al., 2017) reports WDAqua as the winner of the leaderboard with 55.2 F1, however the authors of WDAqua reported 40.0 F1 in their papers (Diefenbach et al., 2017).
7.2 Complementing GPT-3 on QALD-7
Similar to WWQ, we also assess the combination of GPT with WikiSP on QALD-7 as shown in Figure 3. The GPT model used was "text-davinci-002". Since there is no validation set and the test set is already very small, one of the authors who was not involved in training or finetuning the model evaluated GPT-3 on the test set.
GPT-3 is fully accurate on 62% of the questions, 20% incomplete, and 18% wrong. With our approach, we can provide 38% verifiably good answers from WikiSP; the guesses of GPT-3 get an
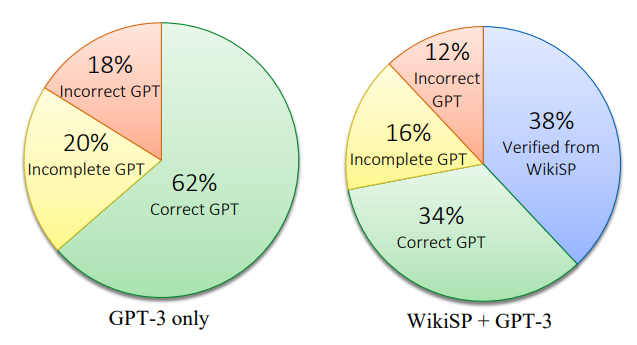
additional 34% correct, 16% incomplete, and only 12% wrong.
7.3 Discussion
We did not conduct error analysis on the performance of QALD-7 as it has no dev set. The author evaluating GPT-3 noted that the test set of QALD-7 is much more complicated than the training data (of just 100 samples), with most of the queries containing multiple properties. This explains the lower accuracy of WikiSP on QALD-7 when compared to WikiWebQuestions, which has a few-shot training data set with a similar distribution as the test set.
This result suggests that the performance of WikiSP depends heavily on a good few-shot training data for fine-tuning the LLMs. We hypothesize that we can increase the performance of WikiSP in handling less popular questions with a better, possibly synthesized, training dataset.
This paper is available on arxiv under CC 4.0 license.